Extract or compute hindcasts and forecasts for a fitted mvgam object
Source: R/forecast.mvgam.R
forecast.mvgam.RdExtract or compute hindcasts and forecasts for a fitted
mvgam object
Usage
# S3 method for mvgam
forecast(object, newdata, data_test, n_cores = 1, type = "response", ...)Arguments
- object
listobject of classmvgamorjsdgam. Seemvgam()- newdata
Optional
dataframeorlistof test data containing the same variables that were included in the originaldataused to fit the model. If included, the covariate information innewdatawill be used to generate forecasts from the fitted model equations. If this samenewdatawas originally included in the call tomvgam, then forecasts have already been produced by the generative model and these will simply be extracted and plotted. However if nonewdatawas supplied to the original model call, an assumption is made that thenewdatasupplied here comes sequentially after the data supplied in the original model (i.e. we assume there is no time gap between the last observation of series 1 in the original data and the first observation for series 1 innewdata)- data_test
Deprecated. Still works in place of
newdatabut users are recommended to usenewdatainstead for more seamless integration intoRworkflows- n_cores
Deprecated. Parallel processing is no longer supported
- type
When this has the value
link(default) the linear predictor is calculated on the link scale. Ifexpectedis used, predictions reflect the expectation of the response (the mean) but ignore uncertainty in the observation process. Whenresponseis used, the predictions take uncertainty in the observation process into account to return predictions on the outcome scale. Whenvarianceis used, the variance of the response with respect to the mean (mean-variance relationship) is returned. Whentype = "terms", each component of the linear predictor is returned separately in the form of alist(possibly with standard errors, ifsummary = TRUE): this includes parametric model components, followed by each smooth component, but excludes any offset and any intercept. Two special cases are also allowed: typelatent_Nwill return the estimated latent abundances from an N-mixture distribution, while typedetectionwill return the estimated detection probability from an N-mixture distribution- ...
Ignored
Value
An object of class mvgam_forecast containing hindcast and
forecast distributions. See mvgam_forecast-class for
details.
Details
Posterior predictions are drawn from the fitted mvgam and
used to simulate a forecast distribution
Examples
# \dontrun{
# Simulate data with 3 series and AR trend model
simdat <- sim_mvgam(n_series = 3, trend_model = AR())
# Fit mvgam model
mod <- mvgam(
y ~ s(season, bs = 'cc', k = 6),
trend_model = AR(),
noncentred = TRUE,
data = simdat$data_train,
chains = 2,
silent = 2
)
# Hindcasts on response scale
hc <- hindcast(mod)
str(hc)
#> List of 15
#> $ call :Class 'formula' language y ~ s(season, bs = "cc", k = 6)
#> .. ..- attr(*, ".Environment")=<environment: 0x5582d734cd18>
#> $ trend_call : NULL
#> $ family : chr "poisson"
#> $ trend_model :List of 7
#> ..$ trend_model: chr "AR1"
#> ..$ ma : logi FALSE
#> ..$ cor : logi FALSE
#> ..$ unit : chr "time"
#> ..$ gr : chr "NA"
#> ..$ subgr : chr "series"
#> ..$ label : language AR()
#> ..- attr(*, "class")= chr "mvgam_trend"
#> ..- attr(*, "param_info")=List of 2
#> .. ..$ param_names: chr [1:8] "trend" "tau" "sigma" "ar1" ...
#> .. ..$ labels : chr [1:8] "trend_estimates" "precision_parameter" "standard_deviation" "autoregressive_coef_1" ...
#> $ drift : logi FALSE
#> $ use_lv : logi FALSE
#> $ fit_engine : chr "stan"
#> $ type : chr "response"
#> $ series_names : chr [1:3] "series_1" "series_2" "series_3"
#> $ train_observations:List of 3
#> ..$ series_1: int [1:75] 5 1 1 3 1 3 3 1 0 0 ...
#> ..$ series_2: int [1:75] 2 2 0 0 4 2 3 1 1 0 ...
#> ..$ series_3: int [1:75] 1 2 1 0 2 5 3 0 0 0 ...
#> $ train_times :List of 3
#> ..$ series_1: int [1:75] 1 2 3 4 5 6 7 8 9 10 ...
#> ..$ series_2: int [1:75] 1 2 3 4 5 6 7 8 9 10 ...
#> ..$ series_3: int [1:75] 1 2 3 4 5 6 7 8 9 10 ...
#> $ test_observations : NULL
#> $ test_times : NULL
#> $ hindcasts :List of 3
#> ..$ series_1: num [1:1000, 1:75] 2 5 2 2 1 3 2 2 3 4 ...
#> .. ..- attr(*, "dimnames")=List of 2
#> .. .. ..$ : NULL
#> .. .. ..$ : chr [1:75] "ypred[1,1]" "ypred[2,1]" "ypred[3,1]" "ypred[4,1]" ...
#> ..$ series_2: num [1:1000, 1:75] 1 2 5 4 0 3 0 3 6 2 ...
#> .. ..- attr(*, "dimnames")=List of 2
#> .. .. ..$ : NULL
#> .. .. ..$ : chr [1:75] "ypred[1,2]" "ypred[2,2]" "ypred[3,2]" "ypred[4,2]" ...
#> ..$ series_3: num [1:1000, 1:75] 2 1 0 5 1 6 2 2 1 2 ...
#> .. ..- attr(*, "dimnames")=List of 2
#> .. .. ..$ : NULL
#> .. .. ..$ : chr [1:75] "ypred[1,3]" "ypred[2,3]" "ypred[3,3]" "ypred[4,3]" ...
#> $ forecasts : NULL
#> - attr(*, "class")= chr "mvgam_forecast"
# Use summary() to extract hindcasts / forecasts for custom plotting
head(summary(hc), 12)
#> # A tibble: 12 × 7
#> series time predQ50 predQ2.5 predQ97.5 truth type
#> <fct> <int> <dbl> <dbl> <dbl> <int> <chr>
#> 1 series_1 1 3 0 8 5 response
#> 2 series_1 2 2 0 6 1 response
#> 3 series_1 3 1 0 3 1 response
#> 4 series_1 4 1 0 4 3 response
#> 5 series_1 5 2 0 7 1 response
#> 6 series_1 6 4 0 9 3 response
#> 7 series_1 7 3 0 7 3 response
#> 8 series_1 8 1 0 4 1 response
#> 9 series_1 9 0 0 2 0 response
#> 10 series_1 10 0 0 2 0 response
#> 11 series_1 11 1 0 4 1 response
#> 12 series_1 12 3 0 8 3 response
# Or just use the plot() function for quick plots
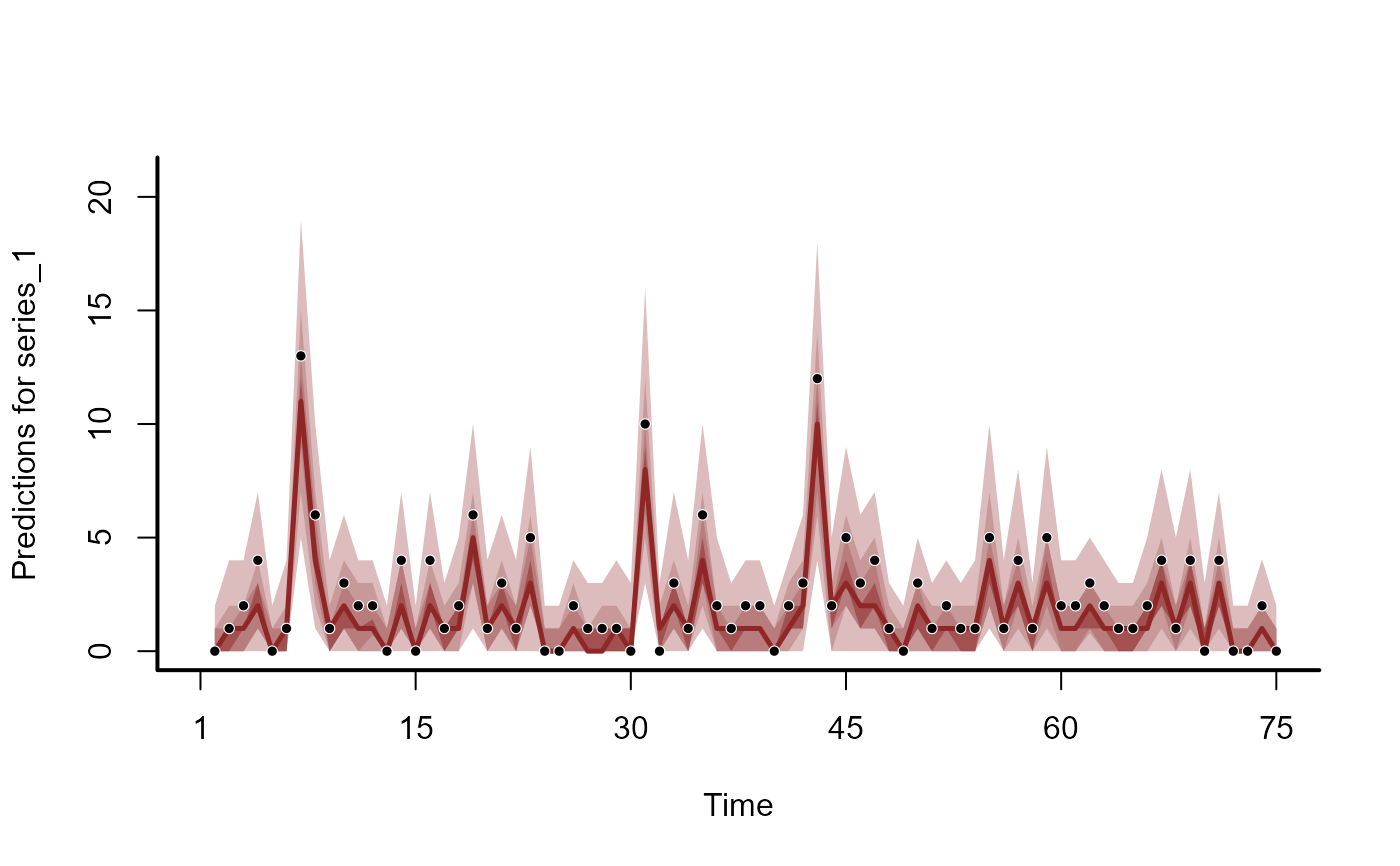
plot(hc, series = 1)
#> No non-missing values in test_observations; cannot calculate forecast score
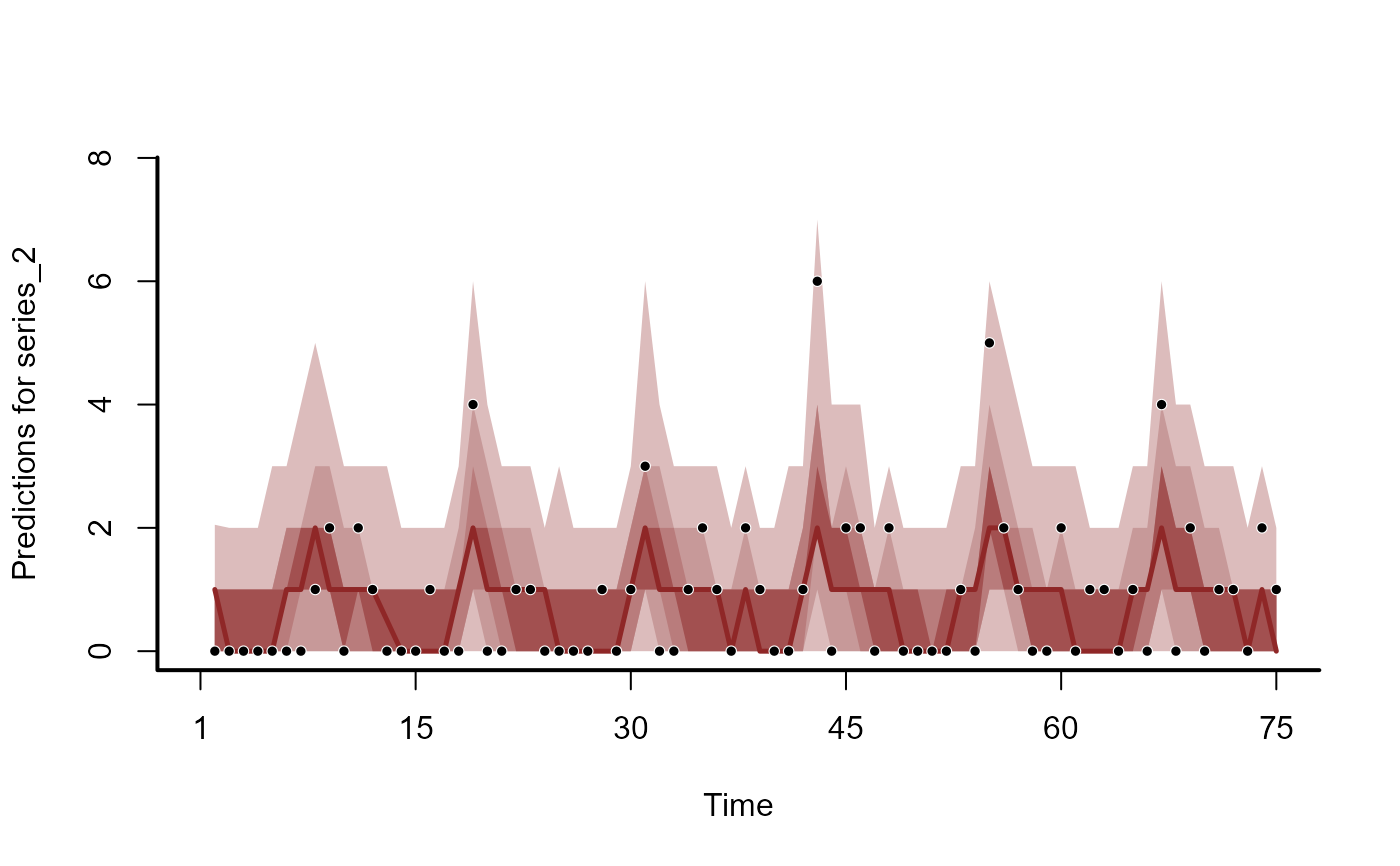
 plot(hc, series = 2)
#> No non-missing values in test_observations; cannot calculate forecast score
plot(hc, series = 2)
#> No non-missing values in test_observations; cannot calculate forecast score
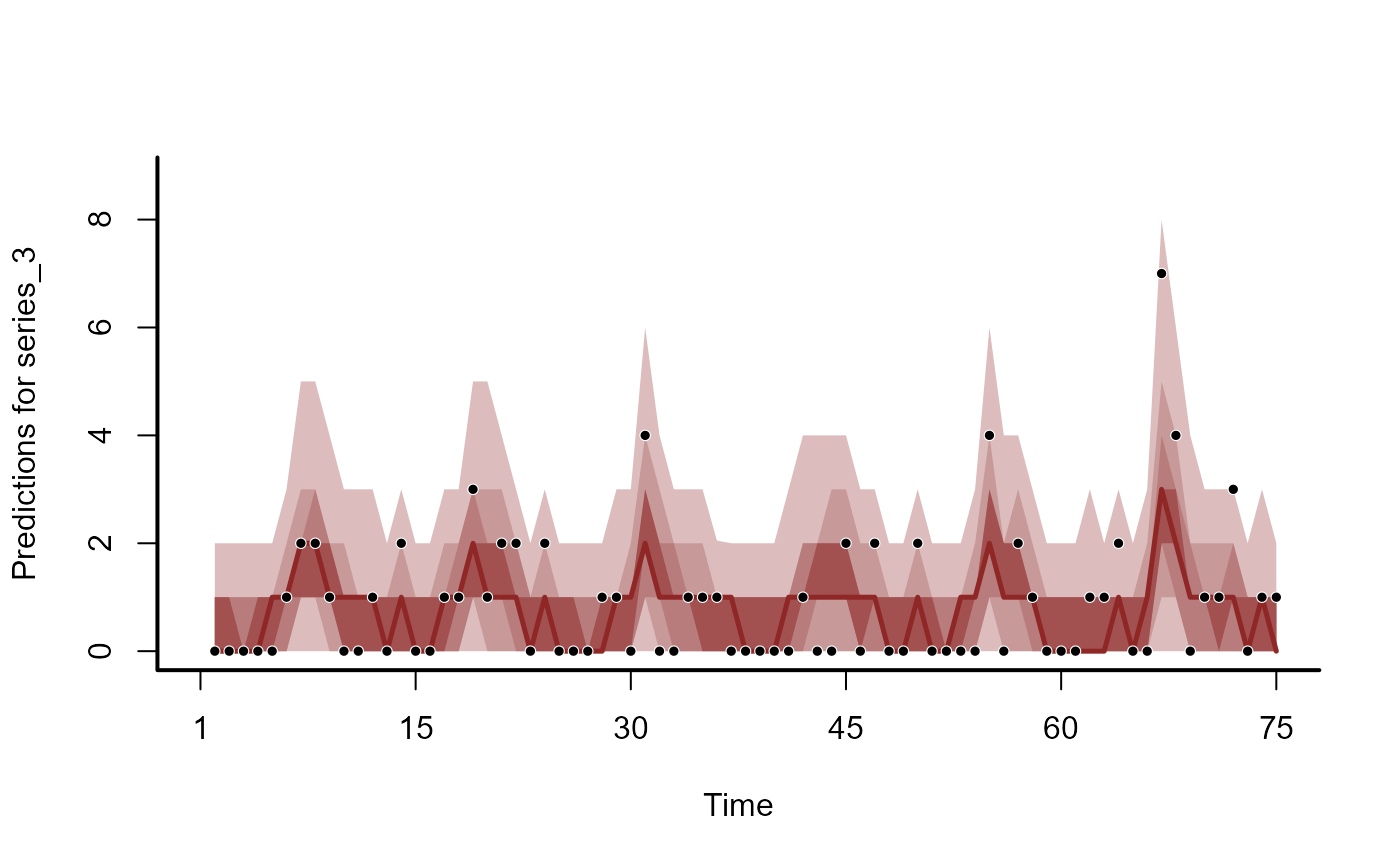
 plot(hc, series = 3)
#> No non-missing values in test_observations; cannot calculate forecast score
plot(hc, series = 3)
#> No non-missing values in test_observations; cannot calculate forecast score
 # Forecasts on response scale
fc <- forecast(
mod,
newdata = simdat$data_test
)
str(fc)
#> List of 16
#> $ call :Class 'formula' language y ~ s(season, bs = "cc", k = 6)
#> .. ..- attr(*, ".Environment")=<environment: 0x5582d734cd18>
#> $ trend_call : NULL
#> $ family : chr "poisson"
#> $ family_pars : NULL
#> $ trend_model :List of 7
#> ..$ trend_model: chr "AR1"
#> ..$ ma : logi FALSE
#> ..$ cor : logi FALSE
#> ..$ unit : chr "time"
#> ..$ gr : chr "NA"
#> ..$ subgr : chr "series"
#> ..$ label : language AR()
#> ..- attr(*, "class")= chr "mvgam_trend"
#> ..- attr(*, "param_info")=List of 2
#> .. ..$ param_names: chr [1:8] "trend" "tau" "sigma" "ar1" ...
#> .. ..$ labels : chr [1:8] "trend_estimates" "precision_parameter" "standard_deviation" "autoregressive_coef_1" ...
#> $ drift : logi FALSE
#> $ use_lv : logi FALSE
#> $ fit_engine : chr "stan"
#> $ type : chr "response"
#> $ series_names : Factor w/ 3 levels "series_1","series_2",..: 1 2 3
#> $ train_observations:List of 3
#> ..$ series_1: int [1:75] 5 1 1 3 1 3 3 1 0 0 ...
#> ..$ series_2: int [1:75] 2 2 0 0 4 2 3 1 1 0 ...
#> ..$ series_3: int [1:75] 1 2 1 0 2 5 3 0 0 0 ...
#> $ train_times :List of 3
#> ..$ series_1: int [1:75] 1 2 3 4 5 6 7 8 9 10 ...
#> ..$ series_2: int [1:75] 1 2 3 4 5 6 7 8 9 10 ...
#> ..$ series_3: int [1:75] 1 2 3 4 5 6 7 8 9 10 ...
#> $ test_observations :List of 3
#> ..$ series_1: int [1:25] 1 2 1 2 0 0 0 0 5 10 ...
#> ..$ series_2: int [1:25] 0 6 3 2 1 0 0 2 4 3 ...
#> ..$ series_3: int [1:25] 2 1 7 1 0 0 1 2 4 6 ...
#> $ test_times :List of 3
#> ..$ series_1: int [1:25] 76 77 78 79 80 81 82 83 84 85 ...
#> ..$ series_2: int [1:25] 76 77 78 79 80 81 82 83 84 85 ...
#> ..$ series_3: int [1:25] 76 77 78 79 80 81 82 83 84 85 ...
#> $ hindcasts :List of 3
#> ..$ series_1: num [1:1000, 1:75] 2 5 2 2 1 3 2 2 3 4 ...
#> .. ..- attr(*, "dimnames")=List of 2
#> .. .. ..$ : NULL
#> .. .. ..$ : chr [1:75] "ypred[1,1]" "ypred[2,1]" "ypred[3,1]" "ypred[4,1]" ...
#> ..$ series_2: num [1:1000, 1:75] 1 2 5 4 0 3 0 3 6 2 ...
#> .. ..- attr(*, "dimnames")=List of 2
#> .. .. ..$ : NULL
#> .. .. ..$ : chr [1:75] "ypred[1,2]" "ypred[2,2]" "ypred[3,2]" "ypred[4,2]" ...
#> ..$ series_3: num [1:1000, 1:75] 2 1 0 5 1 6 2 2 1 2 ...
#> .. ..- attr(*, "dimnames")=List of 2
#> .. .. ..$ : NULL
#> .. .. ..$ : chr [1:75] "ypred[1,3]" "ypred[2,3]" "ypred[3,3]" "ypred[4,3]" ...
#> $ forecasts :List of 3
#> ..$ series_1: int [1:1000, 1:25] 0 0 4 1 1 1 1 0 0 2 ...
#> ..$ series_2: int [1:1000, 1:25] 1 4 3 0 1 0 0 1 0 0 ...
#> ..$ series_3: int [1:1000, 1:25] 1 1 0 3 0 2 1 0 1 2 ...
#> - attr(*, "class")= chr "mvgam_forecast"
head(summary(fc), 12)
#> # A tibble: 12 × 7
#> series time predQ50 predQ2.5 predQ97.5 truth type
#> <fct> <int> <dbl> <dbl> <dbl> <int> <chr>
#> 1 series_1 1 3 0 8 5 response
#> 2 series_1 2 2 0 6 1 response
#> 3 series_1 3 1 0 3 1 response
#> 4 series_1 4 1 0 4 3 response
#> 5 series_1 5 2 0 7 1 response
#> 6 series_1 6 4 0 9 3 response
#> 7 series_1 7 3 0 7 3 response
#> 8 series_1 8 1 0 4 1 response
#> 9 series_1 9 0 0 2 0 response
#> 10 series_1 10 0 0 2 0 response
#> 11 series_1 11 1 0 4 1 response
#> 12 series_1 12 3 0 8 3 response
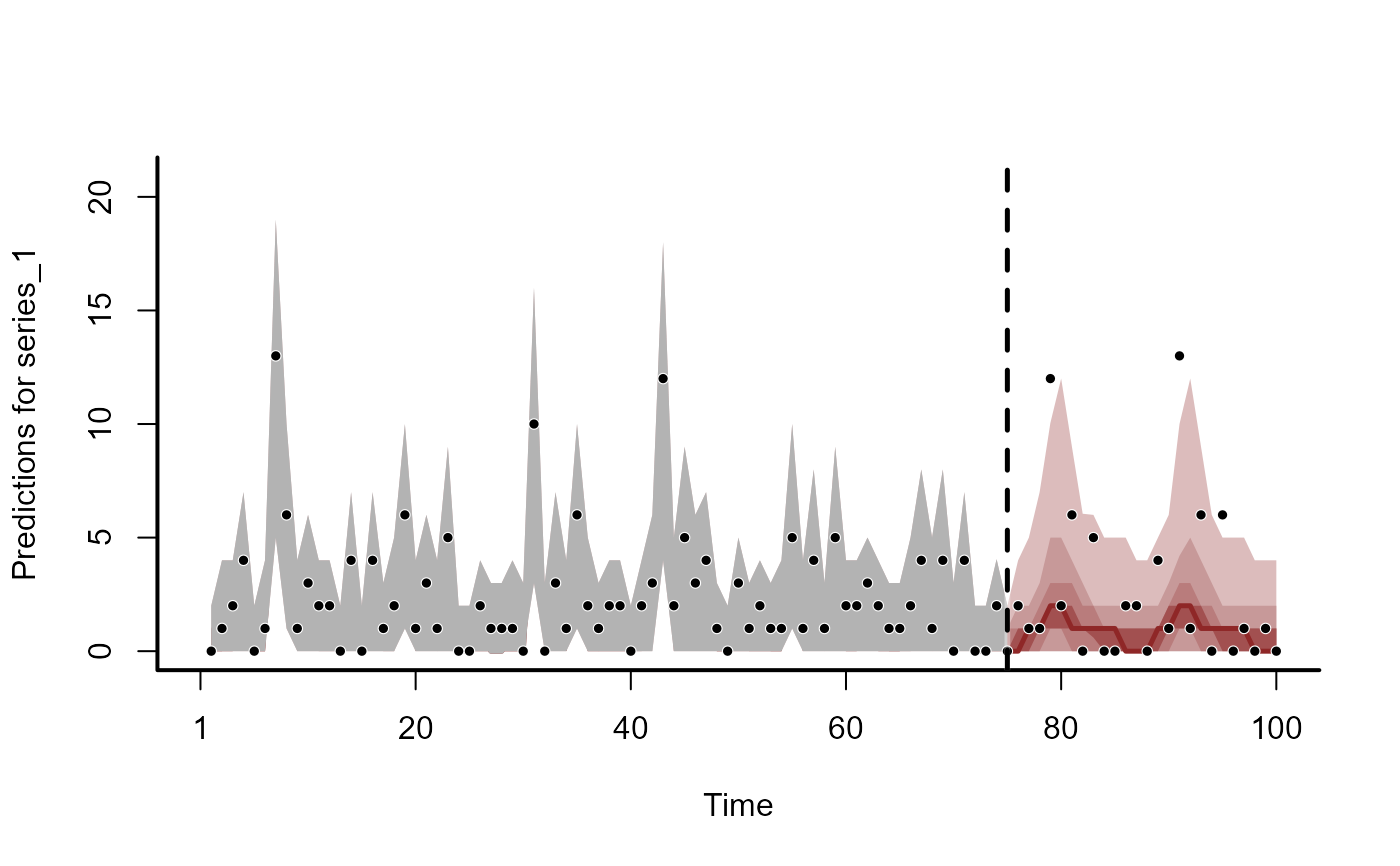
plot(fc, series = 1)
#> Out of sample DRPS:
#> 24.342739
# Forecasts on response scale
fc <- forecast(
mod,
newdata = simdat$data_test
)
str(fc)
#> List of 16
#> $ call :Class 'formula' language y ~ s(season, bs = "cc", k = 6)
#> .. ..- attr(*, ".Environment")=<environment: 0x5582d734cd18>
#> $ trend_call : NULL
#> $ family : chr "poisson"
#> $ family_pars : NULL
#> $ trend_model :List of 7
#> ..$ trend_model: chr "AR1"
#> ..$ ma : logi FALSE
#> ..$ cor : logi FALSE
#> ..$ unit : chr "time"
#> ..$ gr : chr "NA"
#> ..$ subgr : chr "series"
#> ..$ label : language AR()
#> ..- attr(*, "class")= chr "mvgam_trend"
#> ..- attr(*, "param_info")=List of 2
#> .. ..$ param_names: chr [1:8] "trend" "tau" "sigma" "ar1" ...
#> .. ..$ labels : chr [1:8] "trend_estimates" "precision_parameter" "standard_deviation" "autoregressive_coef_1" ...
#> $ drift : logi FALSE
#> $ use_lv : logi FALSE
#> $ fit_engine : chr "stan"
#> $ type : chr "response"
#> $ series_names : Factor w/ 3 levels "series_1","series_2",..: 1 2 3
#> $ train_observations:List of 3
#> ..$ series_1: int [1:75] 5 1 1 3 1 3 3 1 0 0 ...
#> ..$ series_2: int [1:75] 2 2 0 0 4 2 3 1 1 0 ...
#> ..$ series_3: int [1:75] 1 2 1 0 2 5 3 0 0 0 ...
#> $ train_times :List of 3
#> ..$ series_1: int [1:75] 1 2 3 4 5 6 7 8 9 10 ...
#> ..$ series_2: int [1:75] 1 2 3 4 5 6 7 8 9 10 ...
#> ..$ series_3: int [1:75] 1 2 3 4 5 6 7 8 9 10 ...
#> $ test_observations :List of 3
#> ..$ series_1: int [1:25] 1 2 1 2 0 0 0 0 5 10 ...
#> ..$ series_2: int [1:25] 0 6 3 2 1 0 0 2 4 3 ...
#> ..$ series_3: int [1:25] 2 1 7 1 0 0 1 2 4 6 ...
#> $ test_times :List of 3
#> ..$ series_1: int [1:25] 76 77 78 79 80 81 82 83 84 85 ...
#> ..$ series_2: int [1:25] 76 77 78 79 80 81 82 83 84 85 ...
#> ..$ series_3: int [1:25] 76 77 78 79 80 81 82 83 84 85 ...
#> $ hindcasts :List of 3
#> ..$ series_1: num [1:1000, 1:75] 2 5 2 2 1 3 2 2 3 4 ...
#> .. ..- attr(*, "dimnames")=List of 2
#> .. .. ..$ : NULL
#> .. .. ..$ : chr [1:75] "ypred[1,1]" "ypred[2,1]" "ypred[3,1]" "ypred[4,1]" ...
#> ..$ series_2: num [1:1000, 1:75] 1 2 5 4 0 3 0 3 6 2 ...
#> .. ..- attr(*, "dimnames")=List of 2
#> .. .. ..$ : NULL
#> .. .. ..$ : chr [1:75] "ypred[1,2]" "ypred[2,2]" "ypred[3,2]" "ypred[4,2]" ...
#> ..$ series_3: num [1:1000, 1:75] 2 1 0 5 1 6 2 2 1 2 ...
#> .. ..- attr(*, "dimnames")=List of 2
#> .. .. ..$ : NULL
#> .. .. ..$ : chr [1:75] "ypred[1,3]" "ypred[2,3]" "ypred[3,3]" "ypred[4,3]" ...
#> $ forecasts :List of 3
#> ..$ series_1: int [1:1000, 1:25] 0 0 4 1 1 1 1 0 0 2 ...
#> ..$ series_2: int [1:1000, 1:25] 1 4 3 0 1 0 0 1 0 0 ...
#> ..$ series_3: int [1:1000, 1:25] 1 1 0 3 0 2 1 0 1 2 ...
#> - attr(*, "class")= chr "mvgam_forecast"
head(summary(fc), 12)
#> # A tibble: 12 × 7
#> series time predQ50 predQ2.5 predQ97.5 truth type
#> <fct> <int> <dbl> <dbl> <dbl> <int> <chr>
#> 1 series_1 1 3 0 8 5 response
#> 2 series_1 2 2 0 6 1 response
#> 3 series_1 3 1 0 3 1 response
#> 4 series_1 4 1 0 4 3 response
#> 5 series_1 5 2 0 7 1 response
#> 6 series_1 6 4 0 9 3 response
#> 7 series_1 7 3 0 7 3 response
#> 8 series_1 8 1 0 4 1 response
#> 9 series_1 9 0 0 2 0 response
#> 10 series_1 10 0 0 2 0 response
#> 11 series_1 11 1 0 4 1 response
#> 12 series_1 12 3 0 8 3 response
plot(fc, series = 1)
#> Out of sample DRPS:
#> 24.342739
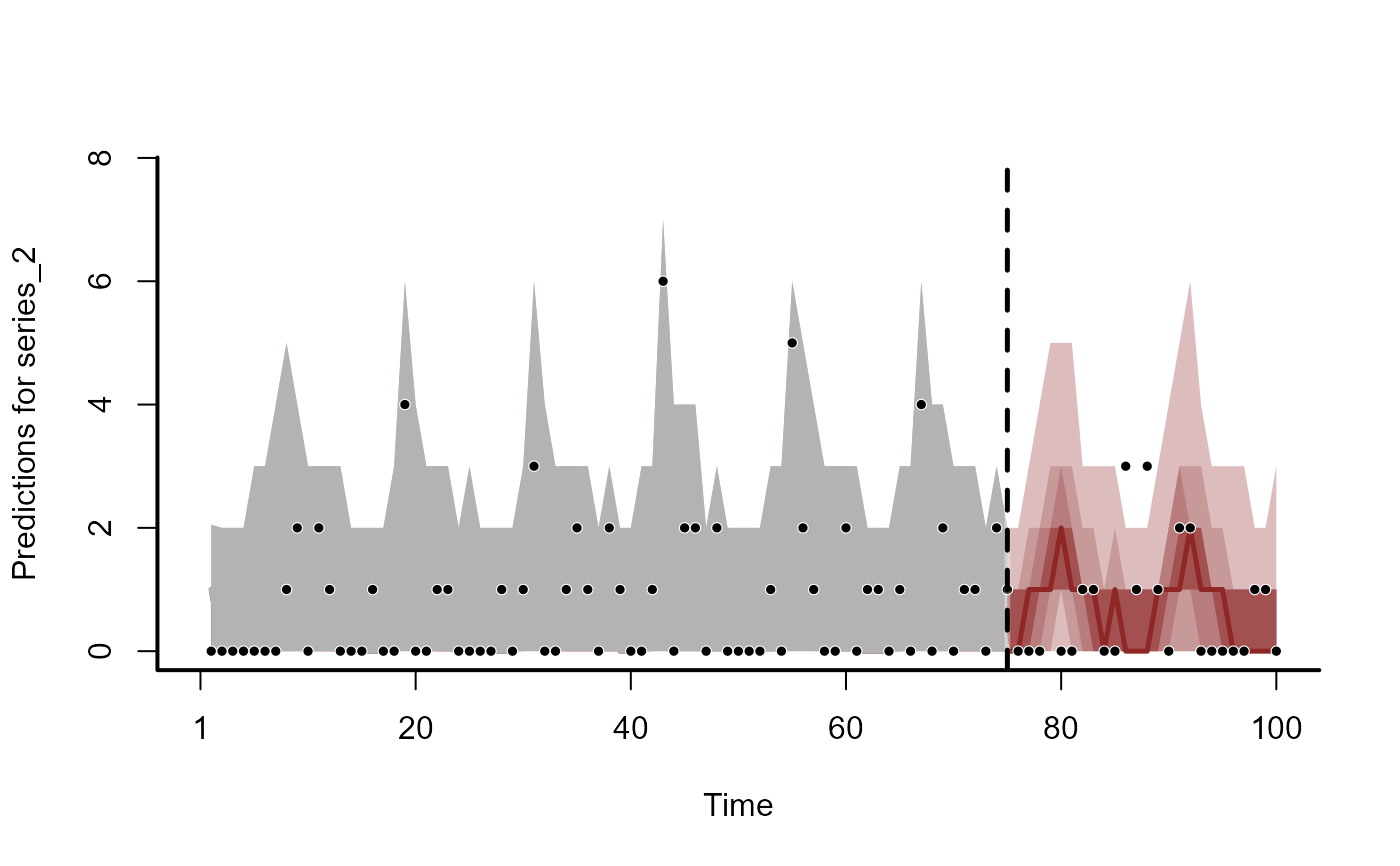
 plot(fc, series = 2)
#> Out of sample DRPS:
#> 19.61456
plot(fc, series = 2)
#> Out of sample DRPS:
#> 19.61456
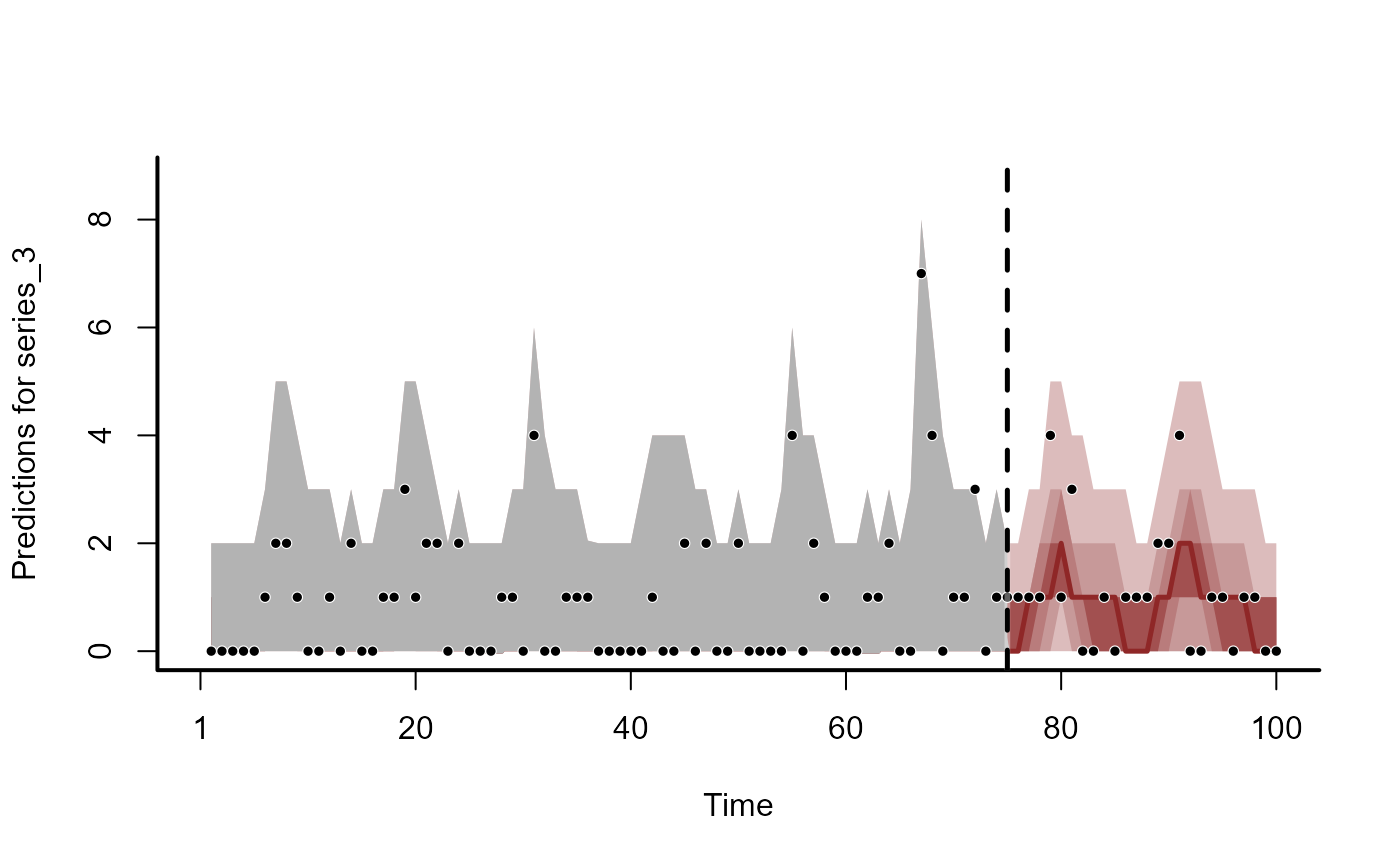
 plot(fc, series = 3)
#> Out of sample DRPS:
#> 24.541848
plot(fc, series = 3)
#> Out of sample DRPS:
#> 24.541848
 # Forecasts as expectations
fc <- forecast(
mod,
newdata = simdat$data_test,
type = 'expected'
)
head(summary(fc), 12)
#> # A tibble: 12 × 6
#> series time predQ50 predQ2.5 predQ97.5 type
#> <fct> <int> <dbl> <dbl> <dbl> <chr>
#> 1 series_1 1 3.44 2.11 5.95 expected
#> 2 series_1 2 2.07 1.08 3.58 expected
#> 3 series_1 3 1.03 0.539 1.91 expected
#> 4 series_1 4 1.37 0.725 2.70 expected
#> 5 series_1 5 2.52 1.28 4.23 expected
#> 6 series_1 6 3.84 2.15 6.05 expected
#> 7 series_1 7 2.93 1.60 5.01 expected
#> 8 series_1 8 1.05 0.543 1.98 expected
#> 9 series_1 9 0.336 0.145 0.673 expected
#> 10 series_1 10 0.306 0.133 0.645 expected
#> 11 series_1 11 1.08 0.507 2.05 expected
#> 12 series_1 12 3.18 1.89 5.35 expected
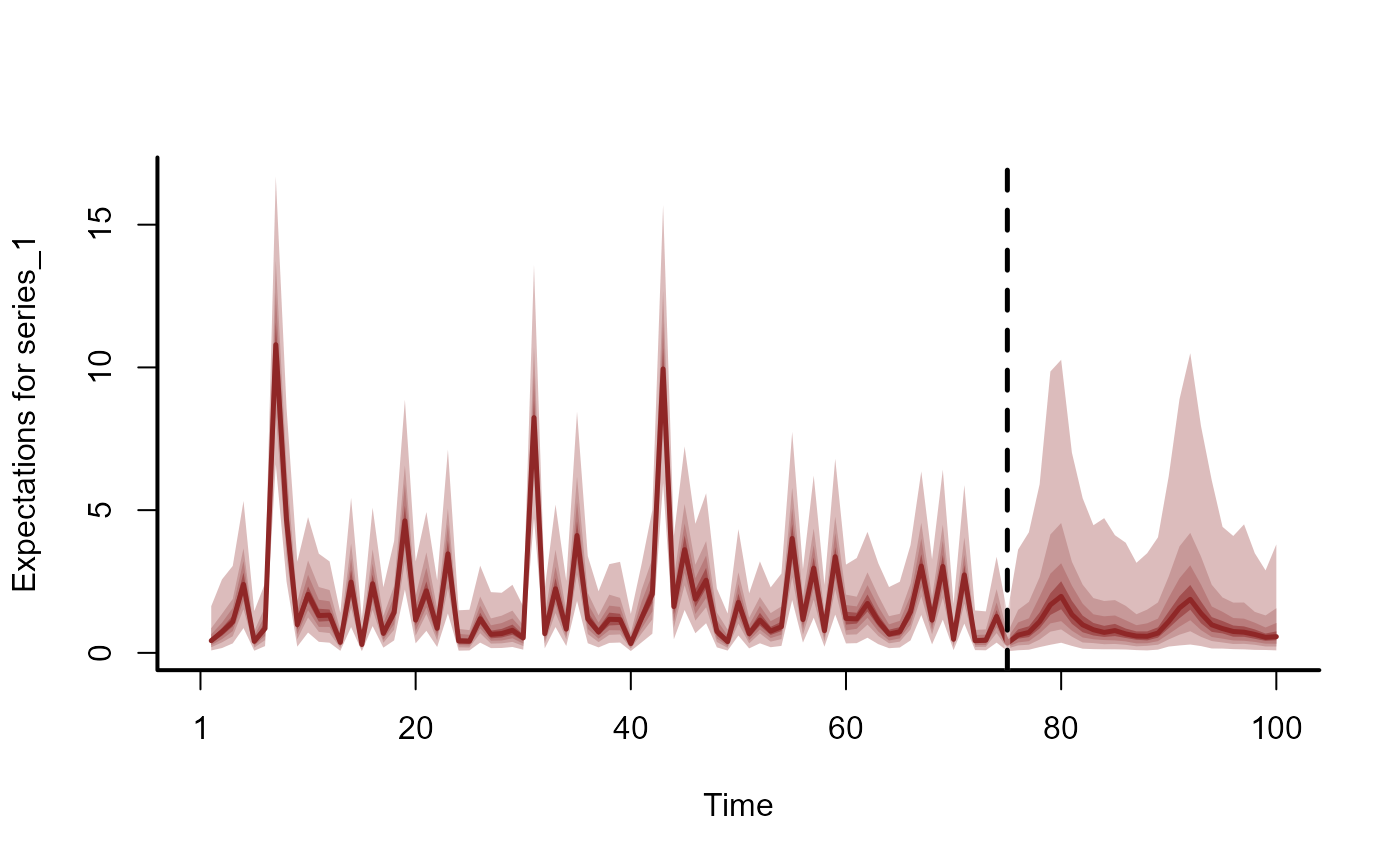
plot(fc, series = 1)
# Forecasts as expectations
fc <- forecast(
mod,
newdata = simdat$data_test,
type = 'expected'
)
head(summary(fc), 12)
#> # A tibble: 12 × 6
#> series time predQ50 predQ2.5 predQ97.5 type
#> <fct> <int> <dbl> <dbl> <dbl> <chr>
#> 1 series_1 1 3.44 2.11 5.95 expected
#> 2 series_1 2 2.07 1.08 3.58 expected
#> 3 series_1 3 1.03 0.539 1.91 expected
#> 4 series_1 4 1.37 0.725 2.70 expected
#> 5 series_1 5 2.52 1.28 4.23 expected
#> 6 series_1 6 3.84 2.15 6.05 expected
#> 7 series_1 7 2.93 1.60 5.01 expected
#> 8 series_1 8 1.05 0.543 1.98 expected
#> 9 series_1 9 0.336 0.145 0.673 expected
#> 10 series_1 10 0.306 0.133 0.645 expected
#> 11 series_1 11 1.08 0.507 2.05 expected
#> 12 series_1 12 3.18 1.89 5.35 expected
plot(fc, series = 1)
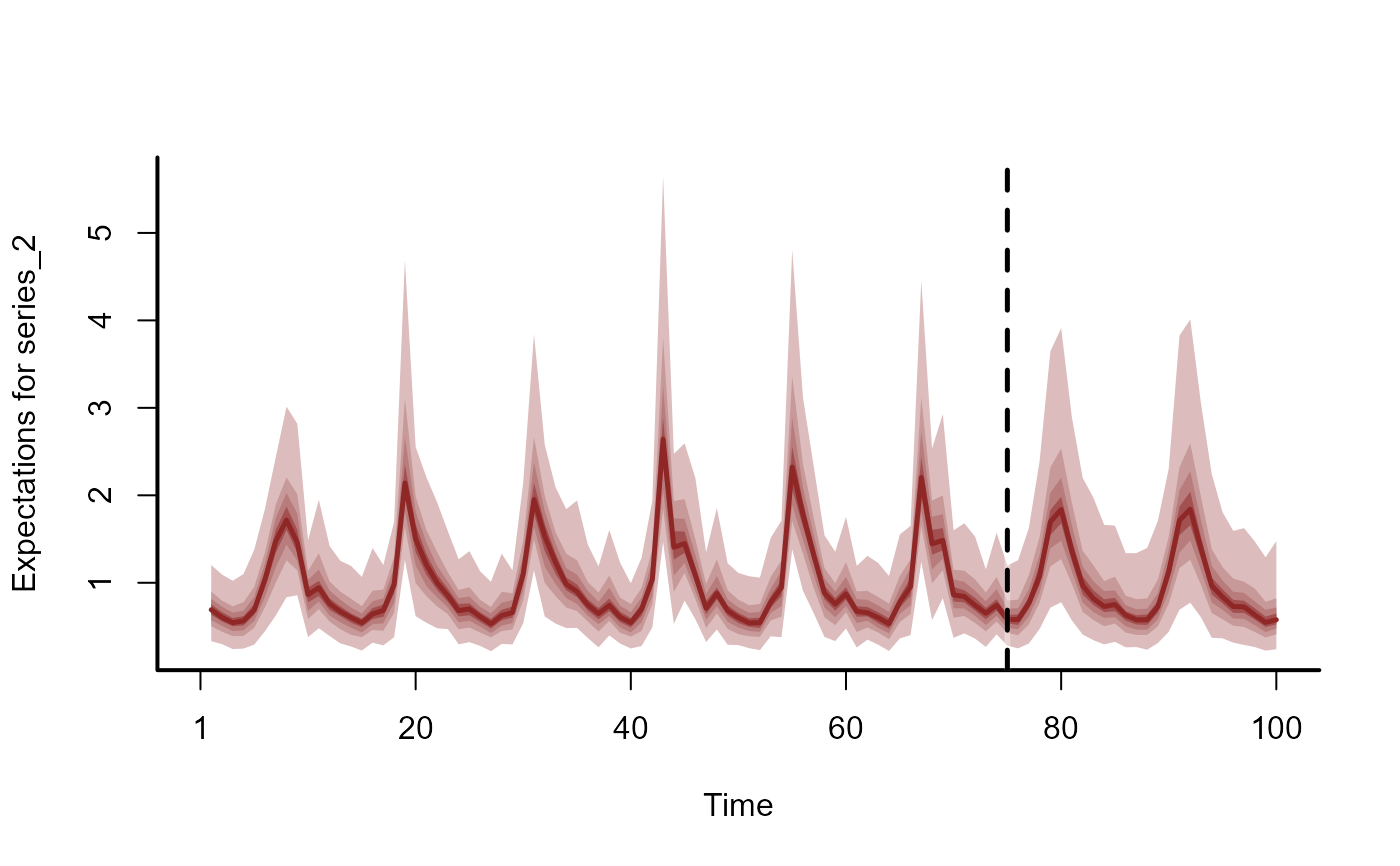
 plot(fc, series = 2)
plot(fc, series = 2)
 plot(fc, series = 3)
plot(fc, series = 3)
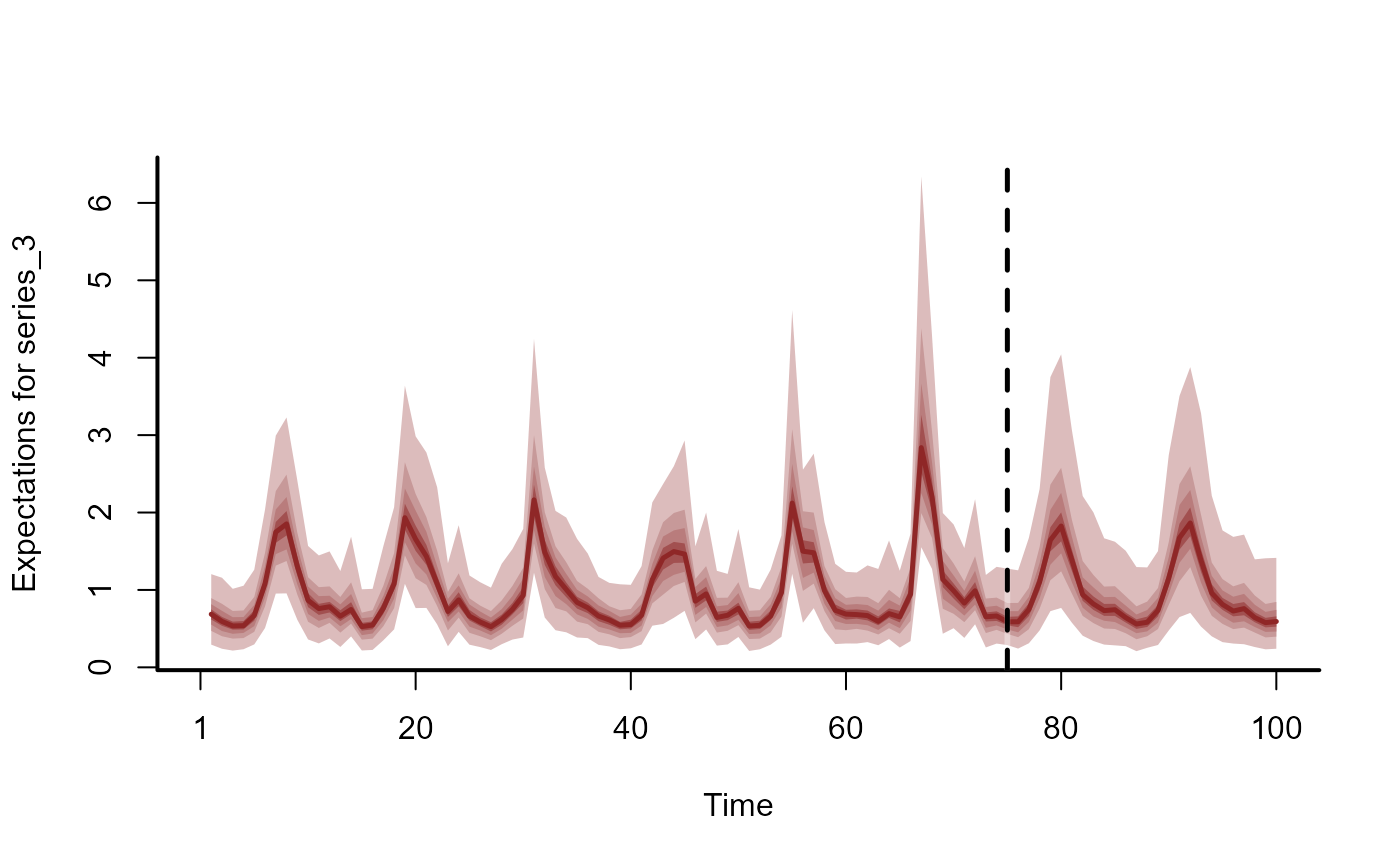 # Dynamic trend extrapolations
fc <- forecast(
mod,
newdata = simdat$data_test,
type = 'trend'
)
head(summary(fc), 12)
#> # A tibble: 12 × 6
#> series time predQ50 predQ2.5 predQ97.5 type
#> <fct> <int> <dbl> <dbl> <dbl> <chr>
#> 1 series_1 1 0.0799 -0.382 0.607 trend
#> 2 series_1 2 -0.0600 -0.723 0.489 trend
#> 3 series_1 3 -0.00119 -0.558 0.582 trend
#> 4 series_1 4 0.0960 -0.476 0.774 trend
#> 5 series_1 5 -0.103 -0.749 0.402 trend
#> 6 series_1 6 -0.110 -0.682 0.352 trend
#> 7 series_1 7 -0.0115 -0.586 0.524 trend
#> 8 series_1 8 -0.0128 -0.630 0.579 trend
#> 9 series_1 9 -0.0299 -0.845 0.571 trend
#> 10 series_1 10 -0.0253 -0.714 0.586 trend
#> 11 series_1 11 -0.0291 -0.696 0.614 trend
#> 12 series_1 12 0.00428 -0.515 0.529 trend
plot(fc, series = 1)
# Dynamic trend extrapolations
fc <- forecast(
mod,
newdata = simdat$data_test,
type = 'trend'
)
head(summary(fc), 12)
#> # A tibble: 12 × 6
#> series time predQ50 predQ2.5 predQ97.5 type
#> <fct> <int> <dbl> <dbl> <dbl> <chr>
#> 1 series_1 1 0.0799 -0.382 0.607 trend
#> 2 series_1 2 -0.0600 -0.723 0.489 trend
#> 3 series_1 3 -0.00119 -0.558 0.582 trend
#> 4 series_1 4 0.0960 -0.476 0.774 trend
#> 5 series_1 5 -0.103 -0.749 0.402 trend
#> 6 series_1 6 -0.110 -0.682 0.352 trend
#> 7 series_1 7 -0.0115 -0.586 0.524 trend
#> 8 series_1 8 -0.0128 -0.630 0.579 trend
#> 9 series_1 9 -0.0299 -0.845 0.571 trend
#> 10 series_1 10 -0.0253 -0.714 0.586 trend
#> 11 series_1 11 -0.0291 -0.696 0.614 trend
#> 12 series_1 12 0.00428 -0.515 0.529 trend
plot(fc, series = 1)
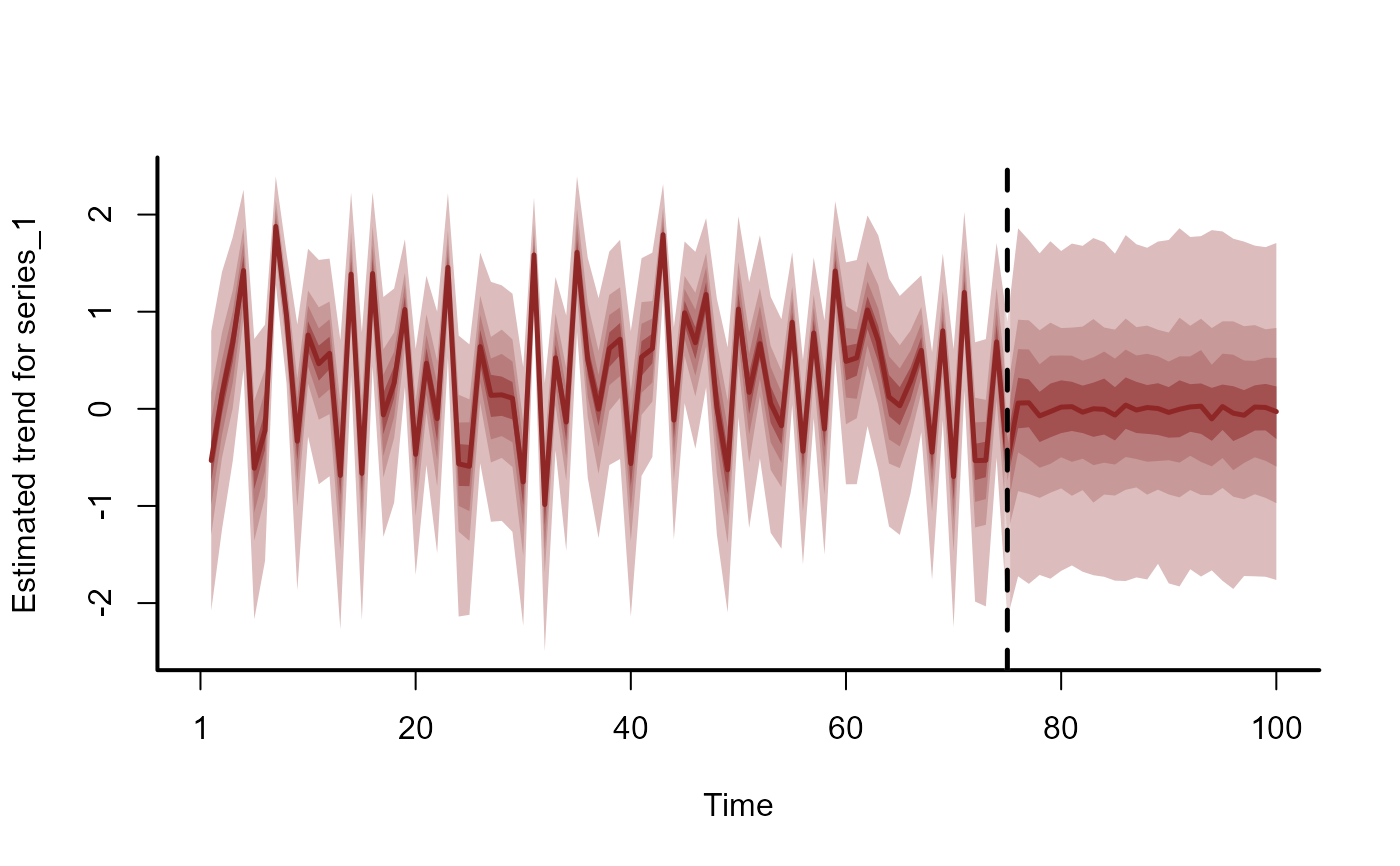 plot(fc, series = 2)
plot(fc, series = 2)
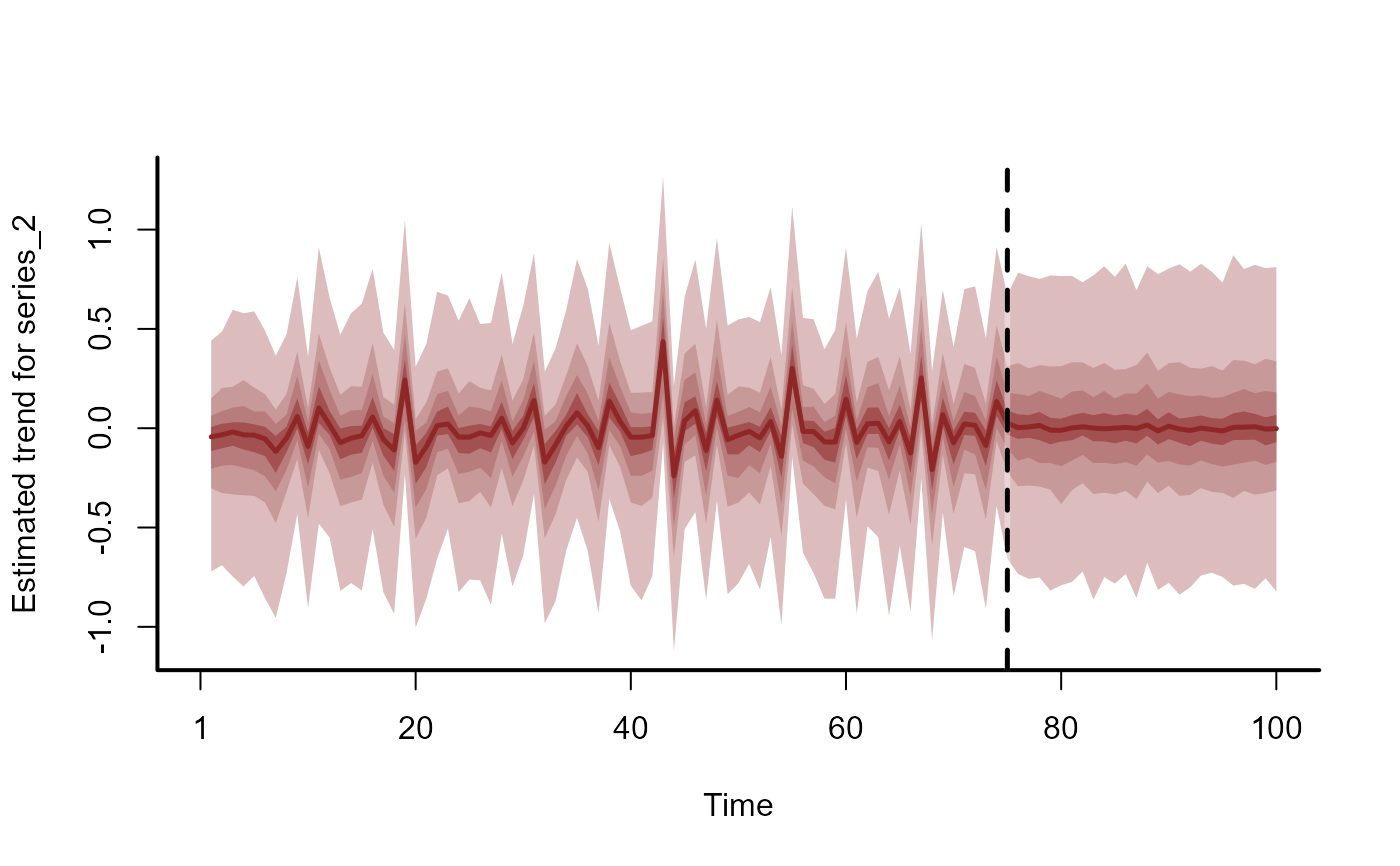 plot(fc, series = 3)
plot(fc, series = 3)
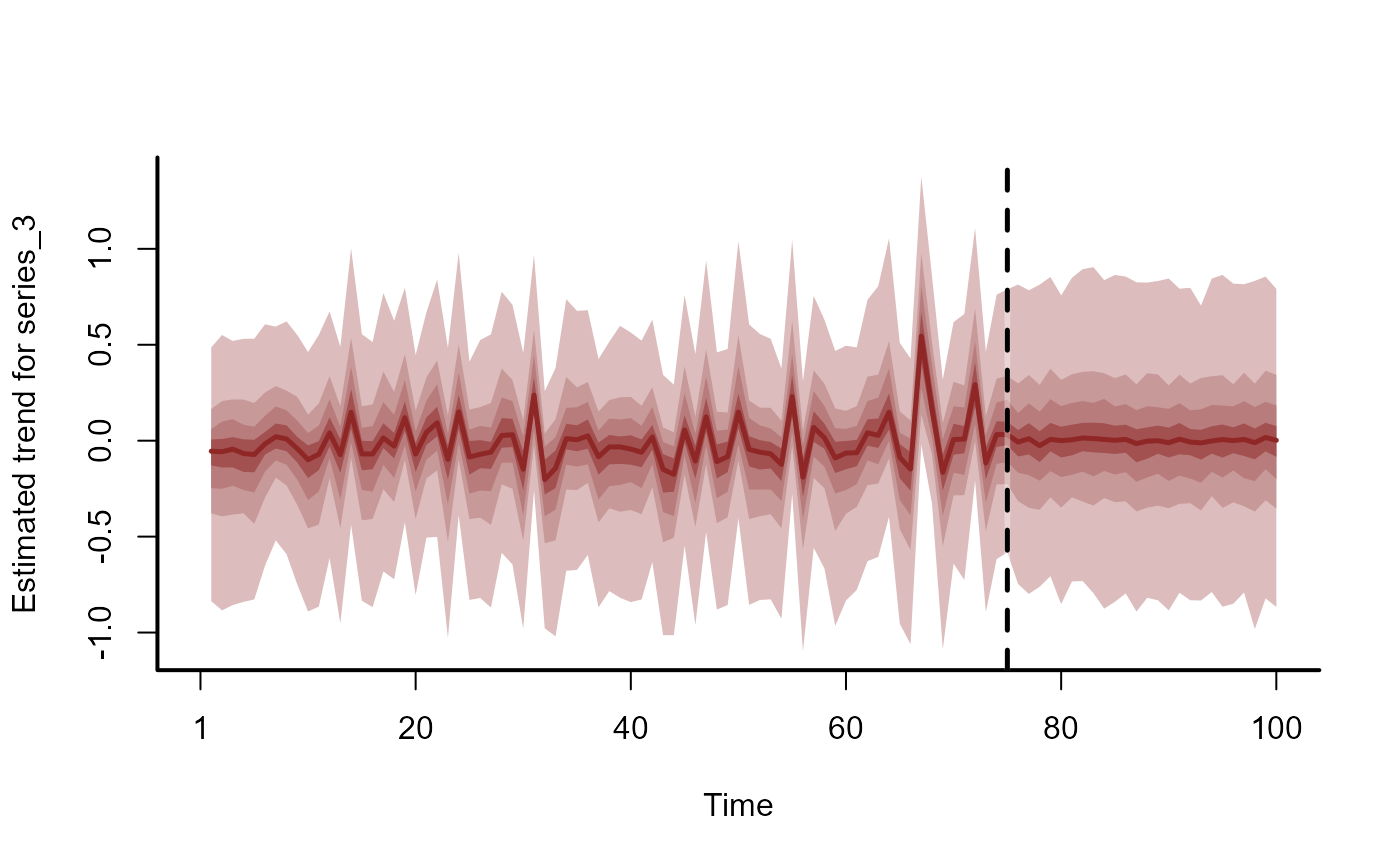 # }
# }