Compute forecast error variance decompositions from
mvgam models with Vector Autoregressive dynamics
Value
See mvgam_fevd-class for a full description of the quantities that are
computed and returned by this function, along with key references.
References
Lütkepohl, H. (2007). New Introduction to Multiple Time Series Analysis. 2nd ed. Springer-Verlag Berlin Heidelberg.
Examples
# \dontrun{
# Simulate some time series that follow a latent VAR(1) process
simdat <- sim_mvgam(
family = gaussian(),
n_series = 4,
trend_model = VAR(cor = TRUE),
prop_trend = 1
)
plot_mvgam_series(data = simdat$data_train, series = "all")
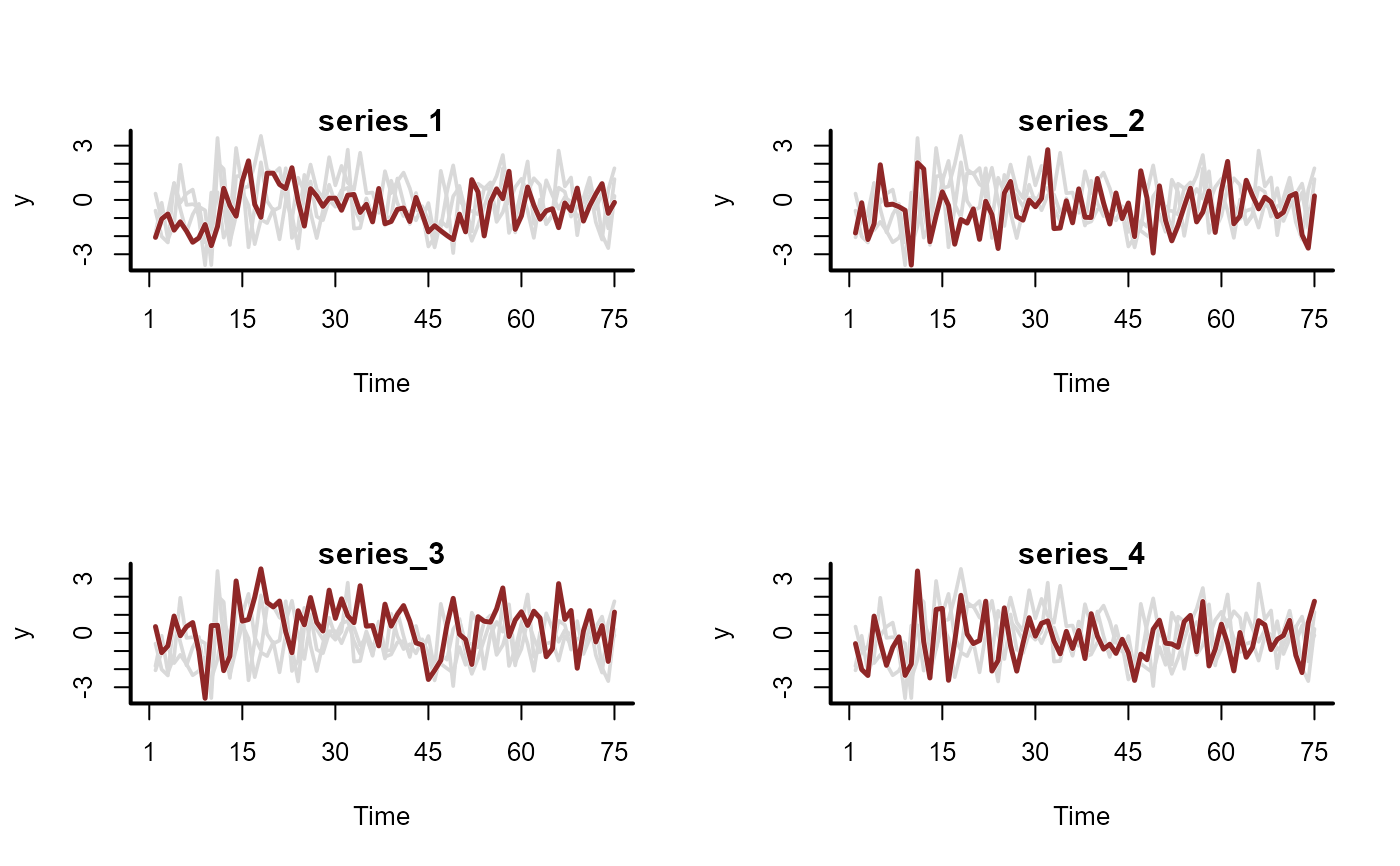 # Fit a model that uses a latent VAR(1)
mod <- mvgam(
formula = y ~ -1,
trend_formula = ~ 1,
trend_model = VAR(cor = TRUE),
family = gaussian(),
data = simdat$data_train,
chains = 2,
silent = 2
)
# Plot the autoregressive coefficient distributions;
# use 'dir = "v"' to arrange the order of facets
# correctly
mcmc_plot(
mod,
variable = 'A',
regex = TRUE,
type = 'hist',
facet_args = list(dir = 'v')
)
#> `stat_bin()` using `bins = 30`. Pick better value `binwidth`.
# Fit a model that uses a latent VAR(1)
mod <- mvgam(
formula = y ~ -1,
trend_formula = ~ 1,
trend_model = VAR(cor = TRUE),
family = gaussian(),
data = simdat$data_train,
chains = 2,
silent = 2
)
# Plot the autoregressive coefficient distributions;
# use 'dir = "v"' to arrange the order of facets
# correctly
mcmc_plot(
mod,
variable = 'A',
regex = TRUE,
type = 'hist',
facet_args = list(dir = 'v')
)
#> `stat_bin()` using `bins = 30`. Pick better value `binwidth`.
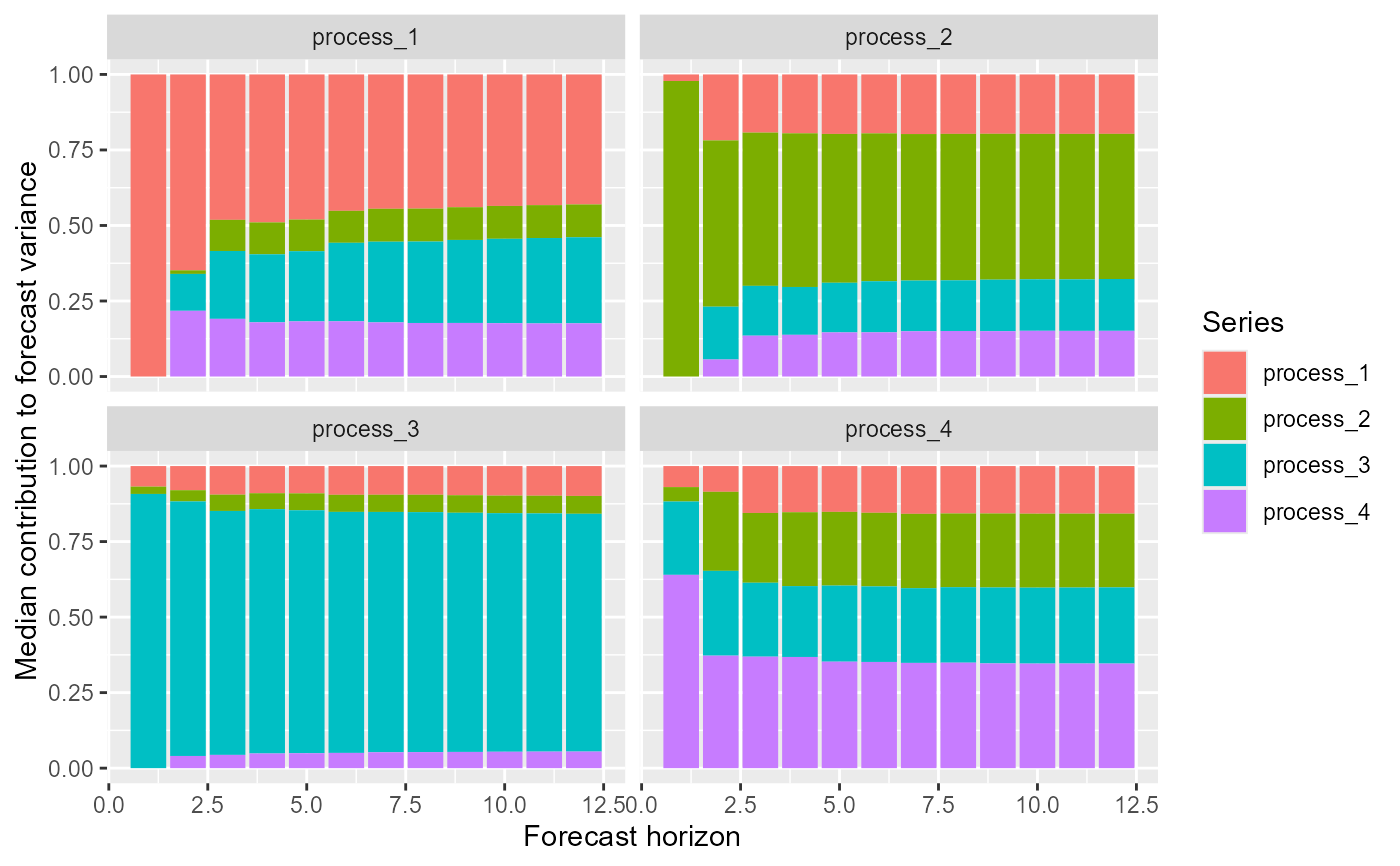 # Calulate forecast error variance decompositions for each series
fevds <- fevd(mod, h = 12)
# Plot median contributions to forecast error variance
plot(fevds)
# Calulate forecast error variance decompositions for each series
fevds <- fevd(mod, h = 12)
# Plot median contributions to forecast error variance
plot(fevds)
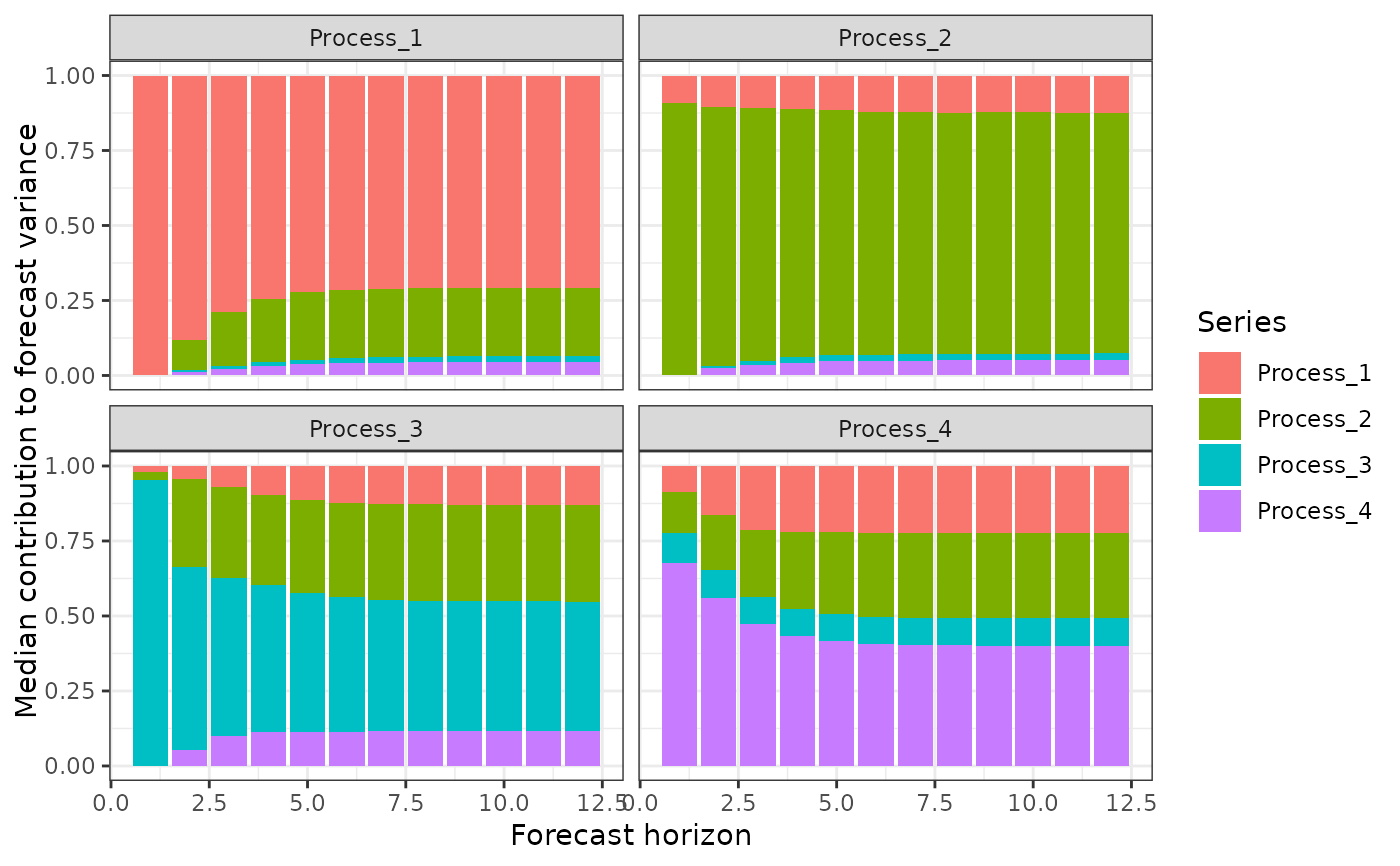 # View a summary of the error variance decompositions
summary(fevds)
#> # A tibble: 192 × 5
#> shock horizon fevdQ50 fevdQ2.5 fevdQ97.5
#> <chr> <int> <dbl> <dbl> <dbl>
#> 1 Process_1 -> Process_1 1 1 1 1
#> 2 Process_1 -> Process_1 2 0.928 0.653 0.995
#> 3 Process_1 -> Process_1 3 0.906 0.638 0.989
#> 4 Process_1 -> Process_1 4 0.890 0.618 0.987
#> 5 Process_1 -> Process_1 5 0.880 0.592 0.986
#> 6 Process_1 -> Process_1 6 0.876 0.591 0.984
#> 7 Process_1 -> Process_1 7 0.872 0.581 0.983
#> 8 Process_1 -> Process_1 8 0.870 0.570 0.983
#> 9 Process_1 -> Process_1 9 0.869 0.570 0.983
#> 10 Process_1 -> Process_1 10 0.868 0.563 0.983
#> # ℹ 182 more rows
# }
# View a summary of the error variance decompositions
summary(fevds)
#> # A tibble: 192 × 5
#> shock horizon fevdQ50 fevdQ2.5 fevdQ97.5
#> <chr> <int> <dbl> <dbl> <dbl>
#> 1 Process_1 -> Process_1 1 1 1 1
#> 2 Process_1 -> Process_1 2 0.928 0.653 0.995
#> 3 Process_1 -> Process_1 3 0.906 0.638 0.989
#> 4 Process_1 -> Process_1 4 0.890 0.618 0.987
#> 5 Process_1 -> Process_1 5 0.880 0.592 0.986
#> 6 Process_1 -> Process_1 6 0.876 0.591 0.984
#> 7 Process_1 -> Process_1 7 0.872 0.581 0.983
#> 8 Process_1 -> Process_1 8 0.870 0.570 0.983
#> 9 Process_1 -> Process_1 9 0.869 0.570 0.983
#> 10 Process_1 -> Process_1 10 0.868 0.563 0.983
#> # ℹ 182 more rows
# }